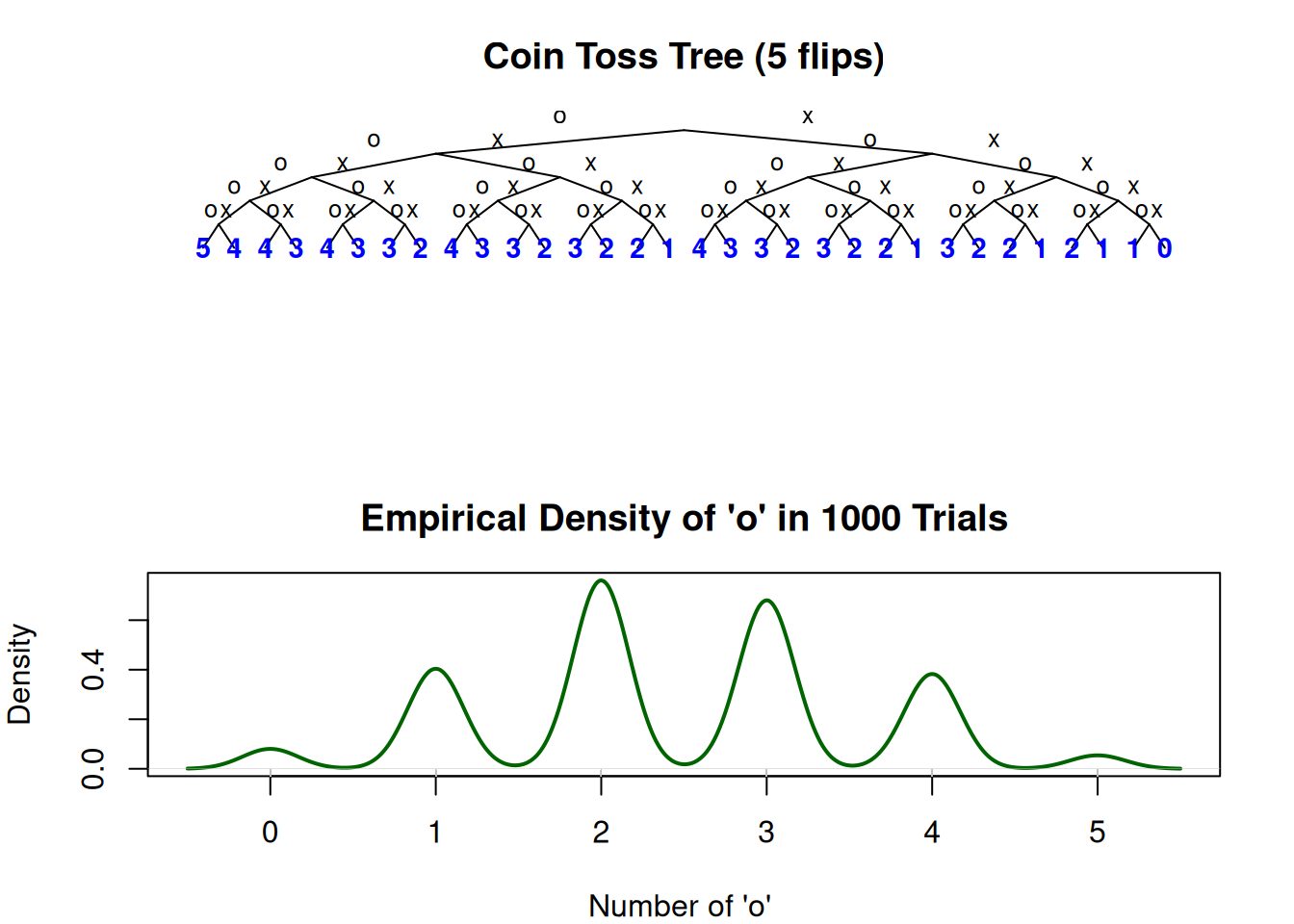
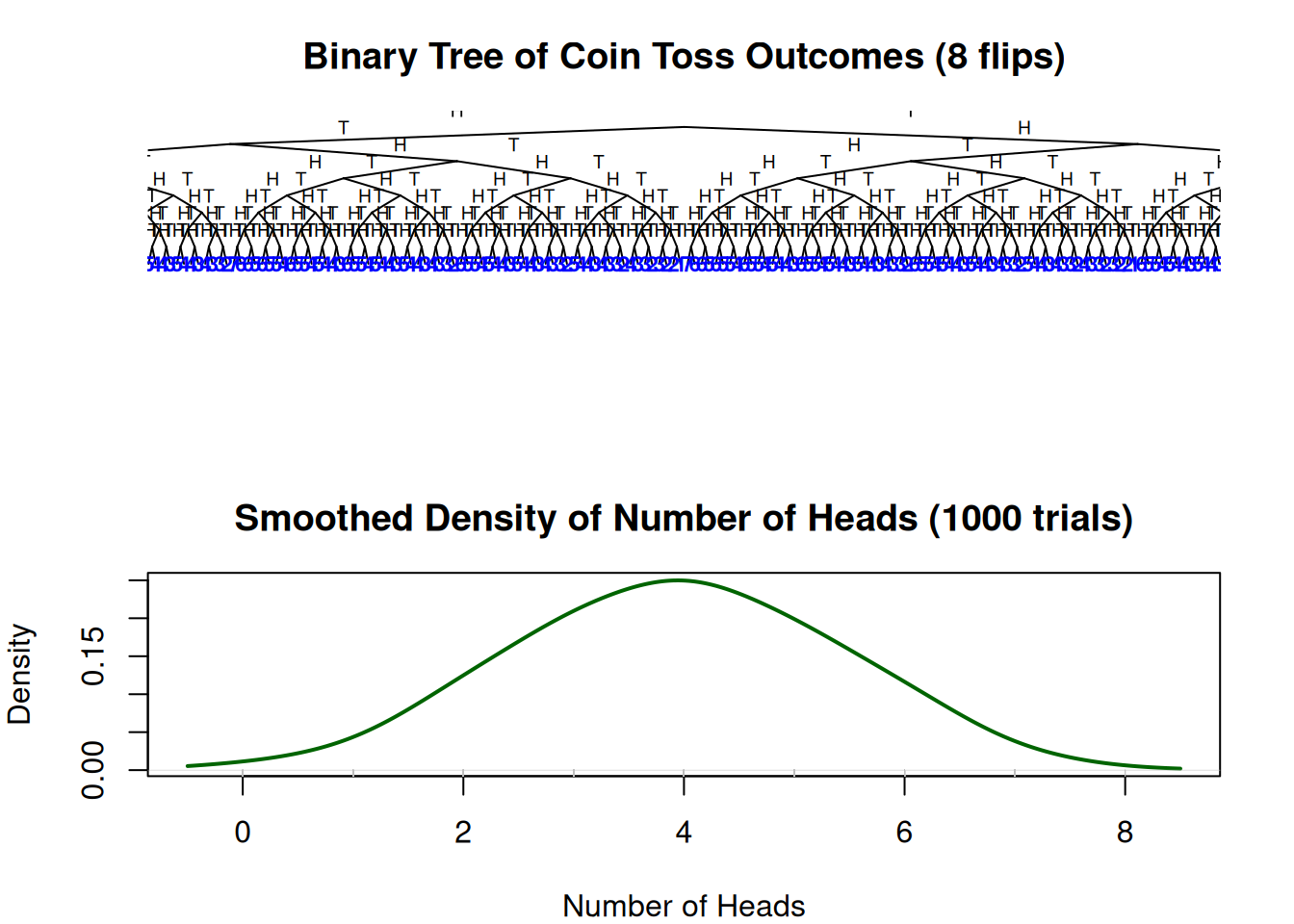
# Function to draw coin toss tree
draw_coin_tree <- function(depth, x_pos, y_pos, dx, num_heads = 0) {
if (depth == 0) {
text(x_pos, y_pos, num_heads, cex = 0.7, col = "blue", font = 2)
} else {
x_left <- x_pos - dx
x_right <- x_pos + dx
y_next <- y_pos - 1
segments(x_pos, y_pos, x_left, y_next)
segments(x_pos, y_pos, x_right, y_next)
text((x_pos + x_left)/2, (y_pos + y_next)/2, "H", pos = 3, cex = 0.6)
text((x_pos + x_right)/2, (y_pos + y_next)/2, "T", pos = 3, cex = 0.6)
draw_coin_tree(depth - 1, x_left, y_next, dx / 2, num_heads + 1)
draw_coin_tree(depth - 1, x_right, y_next, dx / 2, num_heads)
}
}
# Parameters
num_flips <- 8
num_simulations <- 1000
set.seed(42)
# Simulate coin toss outcomes (number of heads per trial)
head_counts <- rbinom(num_simulations, size = num_flips, prob = 0.5)
# Prepare 2-panel layout
par(mfrow = c(2, 1), mar = c(4, 4, 3, 2))
# Plot the coin toss tree
plot(0, 0, type = "n", xlim = c(-140, 140), ylim = c(-9.5, 1.5),
xlab = "", ylab = "", axes = FALSE,
main = "Binary Tree of Coin Toss Outcomes (8 flips)")
draw_coin_tree(depth = num_flips, x_pos = 0, y_pos = 1, dx = 128)
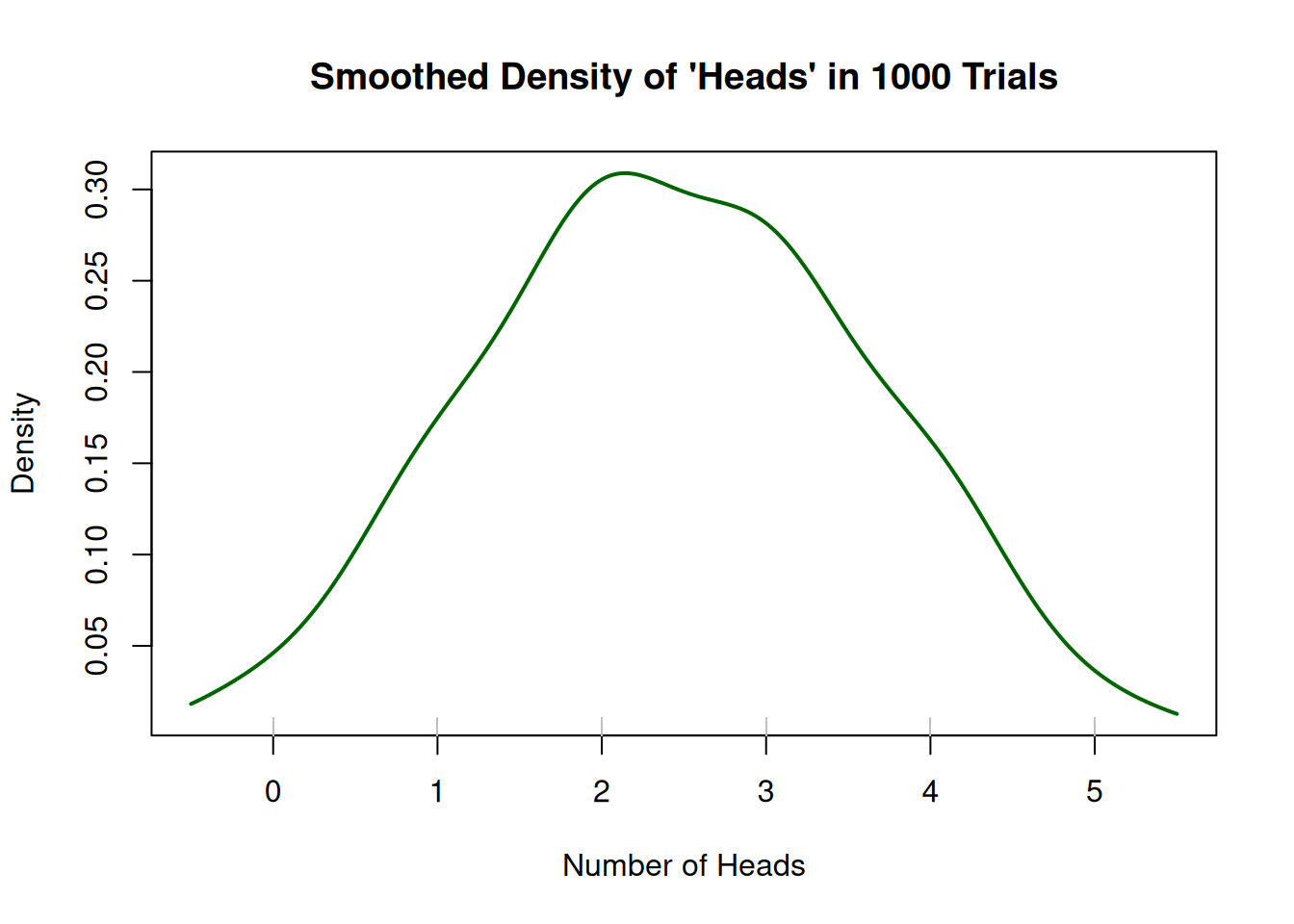
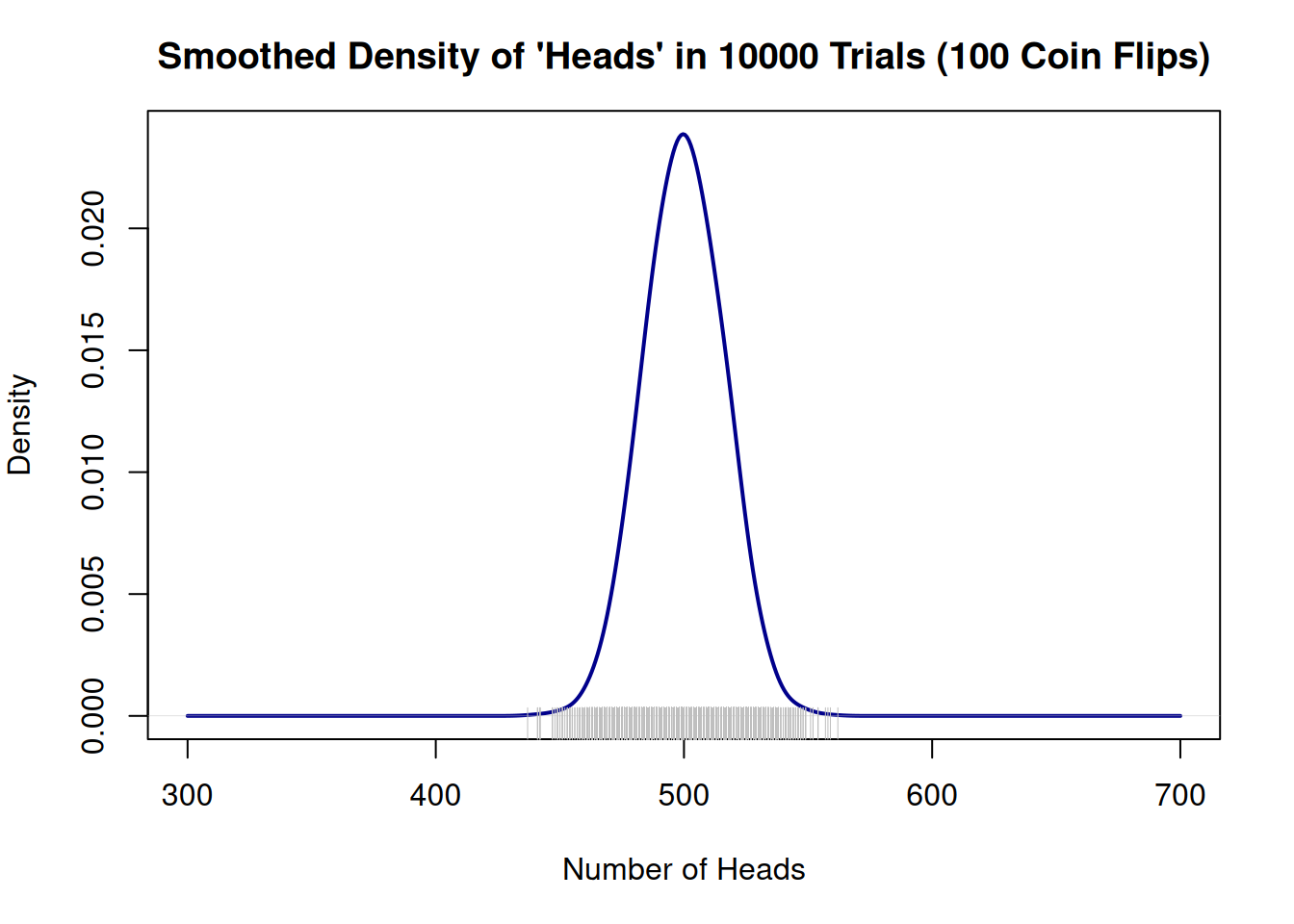
# Estimate and plot smoothed density of head counts
head_density <- density(head_counts, from = -0.5, to = 8.5, adjust = 2)
plot(head_density, main = "Smoothed Density of Number of Heads (1000 trials)",
xlab = "Number of Heads", ylab = "Density", col = "darkgreen", lwd = 2)
rug(head_counts, col = "gray")